
Tabla de contenidos
Algunos sitios web pueden contener una gran cantidad de datos invaluables. Precios de las acciones, detalles del producto, estadísticas deportivas, contactos de la empresa, lo que sea. Si deseas acceder a esta información, deberás copiar y pegar la información manualmente en un nuevo documento. Aquí es donde el web scraping puede ayudar.
¿Qué es el web scraping?
El web scraping se refiere a la extracción de datos de un sitio web. Esta información se recopila y luego se exporta a un formato que sea más útil para el usuario. Ya sea una hoja de cálculo o una API.
Aunque el web scraping e puede hacer manualmente, en la mayoría de los casos, se prefieren las herramientas automatizadas al extraer datos de una web, ya que funcionan mucho más rápido.
Pero en la mayoría de los casos, el web scraping no es una tarea simple. Los sitios web vienen en muchas formas y formas, como resultado, los scrapeadores web varían en funcionalidad y características.
¿Cómo funcionan los Web Scrapers?
Los web scrapers automatizados funcionan de una manera bastante simple pero también compleja. Después de todo, los sitios web están diseñados para que los humanos los entiendan, no las máquinas.
Primero, el scraper web recibirá una o más URL para cargar antes de scrapear. El scrapeador luego carga el código HTML completo de la página en cuestión. Los scrapeadores más avanzados mostrarán todo el sitio web, incluidos los elementos CSS y Javascript.
Luego, extraerá todos los datos de la página o datos específicos seleccionados por el usuario antes de ejecutar el proyecto.
Idealmente, el usuario pasará por el proceso de seleccionar los datos específicos que desea de la página. Por ejemplo, es posible que desee extraer de una página productos de Amazon para obtener precios y modelos, pero no está necesariamente interesado en las reviews de productos.
Por último, el escrapeador web generará todos los datos que se han recopilado en un formato que sea más útil para el usuario.
La mayoría de los scrapeadores web generarán datos en una hoja de cálculo CSV o Excel, mientras que los más avanzados admitirán otros formatos como JSON que se pueden usar para una API.
¿Para qué se usan los Scrapeadores web?
Probablemente puedas pensar en varias formas en las que se pueden usar los Scrapeadores web. Hemos puesto algunos de los más comunes a continuación
- Scrapear los precios de las acciones en una API de aplicación
- Scrapear datos de un localizador de tiendas para crear una lista de ubicaciones de negocios
- Scrapeado de datos de productos de sitios como Amazon o eBay para el análisis de la competencia
- Scrapear estadísticas deportivas para apuestas
- Scrapeado de datos del sitio antes de la migración de un sitio web
- Scrapeado de detalles del producto para comparar precios
- Scrapeado de datos financieros para estudios de mercado y perspectivas
La lista de cosas que puede hacer con el web scraping es casi interminable. Después de todo, se trata de lo que puedes hacer con los datos que has recopilado y de lo valioso que puedes hacerlo.
La mejor herramienta de Web Scraping
Entonces, ahora que conoce los conceptos básicos del web scraping, probablemente te estés preguntando cuál es el mejor web scraper.
La respuesta obvia es que depende .
Cuanto más sepa sobre tus necesidades de scraping, tendrás una mejor idea sobre cuál es el mejor para ti.
Yo utilizo y recomiendo ParseHub. No solo porque se puede descargar GRATIS, sino que viene con un conjunto poderoso de características, incluyendo una interfaz de usuario amigable, y otras cositas que ya veremos.

Cómo extraer datos de un sitio web en una hoja de cálculo con Parsehub
- Descargar ParseHub y tenerlo funcionando en tu computadora.
- Encuentra las páginas web específicas que deseas scrapear o de donde quieres extraer datos. En este ejemplo, utilizaremos la página de resultados de Yelp para restaurantes de comida rápida en Toronto .
Crear un proyecto
- En ParseHub, haga clic en » Nuevo proyecto » e ingrese la URL para trabajar.
- Una vez enviada, la URL se cargará dentro de ParseHub y podrá comenzar a seleccionar la información que desea extraer.
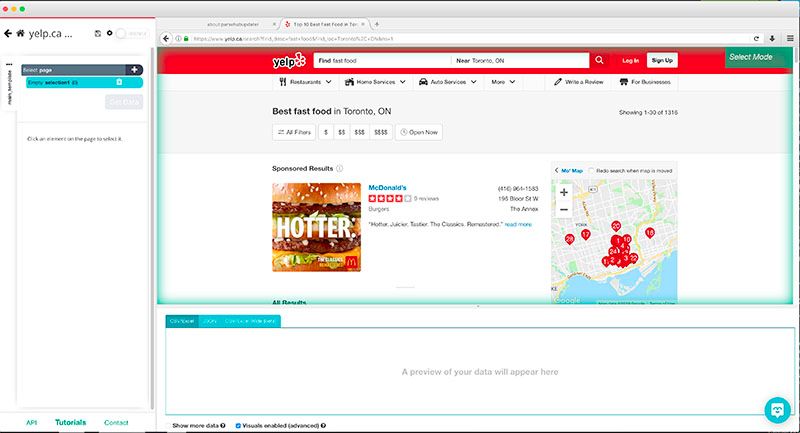
Identificar y seleccionar datos para el web scraping
- Comencemos seleccionando el nombre comercial del primer resultado en la página. Haga esto haciendo clic en él. Luego se volverá verde.
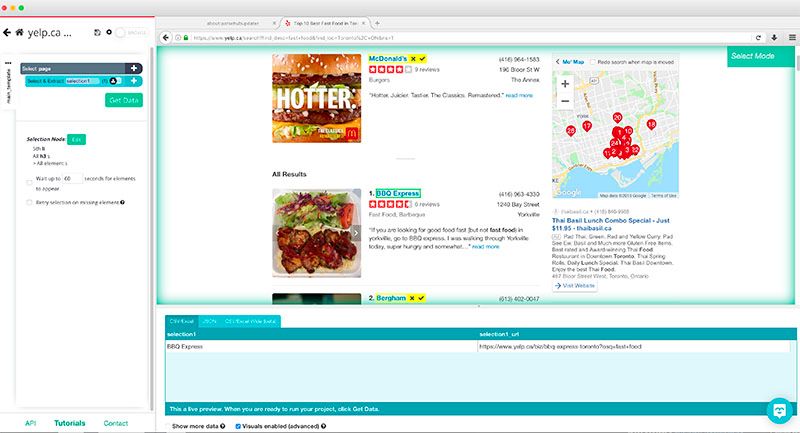
- Notará que todos los nombres comerciales en la página se volverán amarillos. Haga clic en el siguiente para seleccionarlos todos.
- Notará que ParseHub ahora está configurado para extraer el nombre comercial de cada resultado en la página más la URL a la que se está vinculando. Todos los nombres comerciales ahora también serán verdes.
- En la barra lateral izquierda, haga clic en la selección que acaba de crear y cámbiele el nombre a empresa
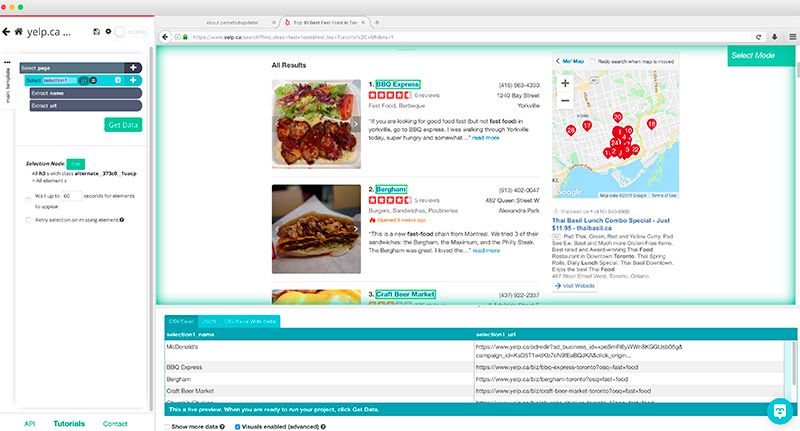
- Luego haga clic en el signo MÁS (+) en la selección y elija la selección relativa. Esto nos permitirá extraer más datos, como la dirección y el número de teléfono de cada empresa.
- Usando la selección relativa, haga clic en el primer nombre comercial y luego en el número de teléfono al lado. Cambie el nombre de esta selección relativa a teléfono.
- Usando la opción de selección Relativa nuevamente, haga lo mismo para la dirección comercial. Cambie el nombre de esta selección relativa a la dirección. Haremos lo mismo para la categoría de negocios.
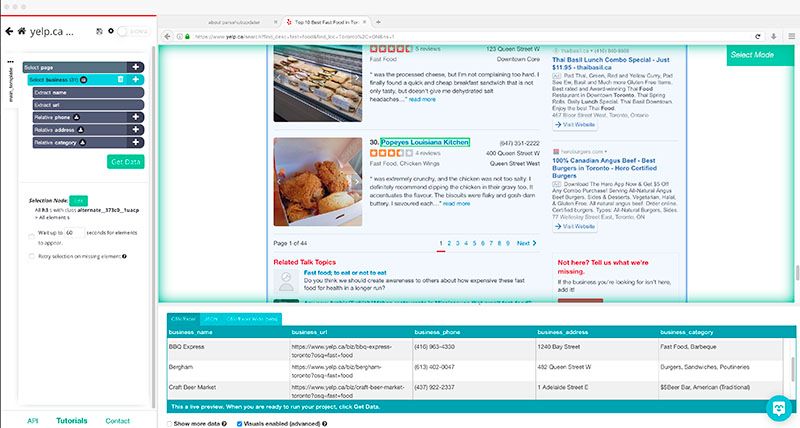
Paginación
Ahora, notará que este método solo capturará la primera página de resultados de búsqueda. Ahora le diremos a ParseHub que elimine las siguientes 5 páginas de resultados.
- Haga clic en el signo MÁS (+) junto al elemento » Seleccionar página «, elija el comando Seleccionar y seleccione el enlace » Siguiente » en la parte inferior de la página que desea scrapear.
- Cambie el nombre de esta selección a Paginación.
- ParseHub extraerá automáticamente la URL de este enlace en la hoja de cálculo. En este caso, eliminaremos estas URL ya que no las necesitamos. Haga clic en el icono junto al nombre de la selección y elimine los 2 comandos de extracción.
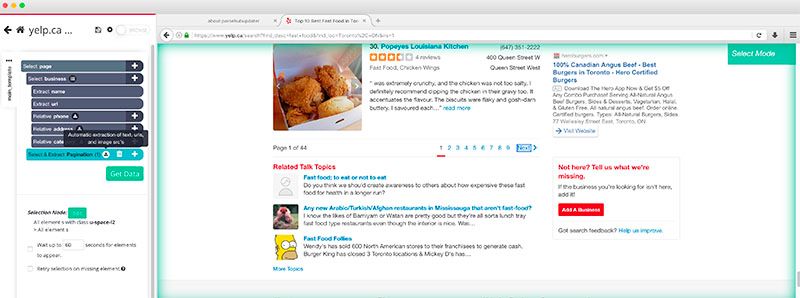
- Ahora, haga clic en el signo MÁS (+) junto a su selección de Paginación y use el comando hacer clic.
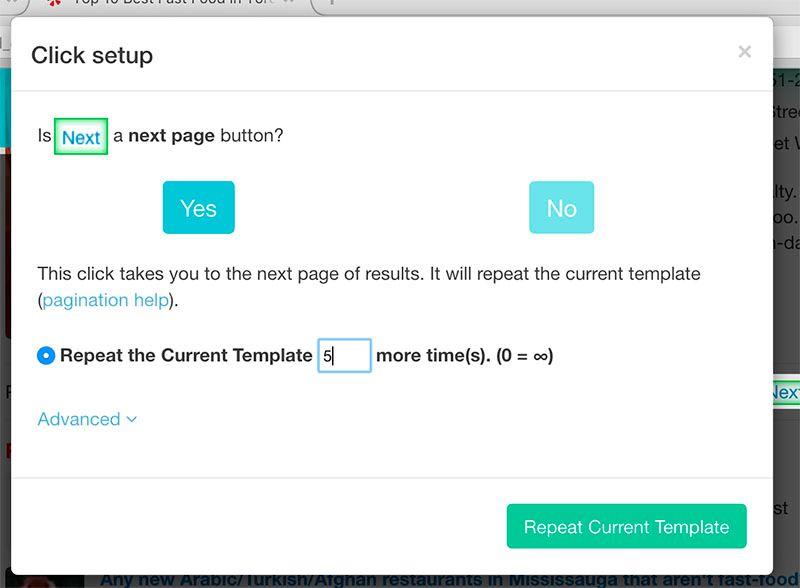
- Aparecerá una ventana preguntando si este es un enlace de Página siguiente . Haga clic en «Sí» e ingrese la cantidad de veces que desea que se repita este ciclo. Para este ejemplo, lo haremos 5 veces. Luego, haga clic en Repetir plantilla actual.
Scrapear y exportar datos
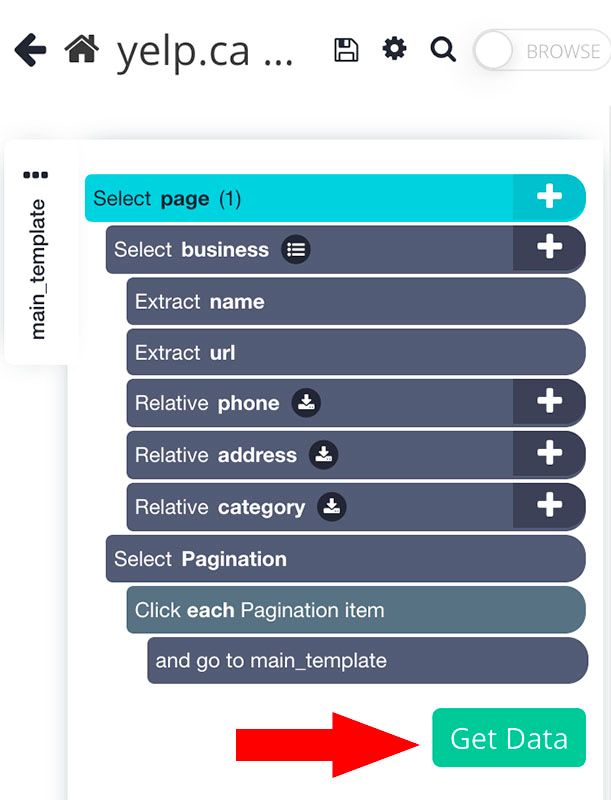
Ahora que ya está todo configurado, es hora de extraer datos.
- Haga clic en el botón verde get data en la barra lateral izquierda
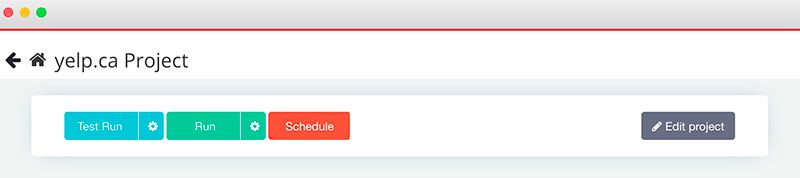
- Aquí puede probar su ejecución, programarla para el futuro o ejecutarla de inmediato. En este caso, lo ejecutaremos de inmediato, aunque recomendamos que siempre pruebe antes de ejecutarlas.
- Puedes esperar en esta pantalla o salir de ParseHub, se te notificará una vez que se complete el web scraping ¡En este caso, nuestra extracción de datos se completó en menos de 2 minutos!
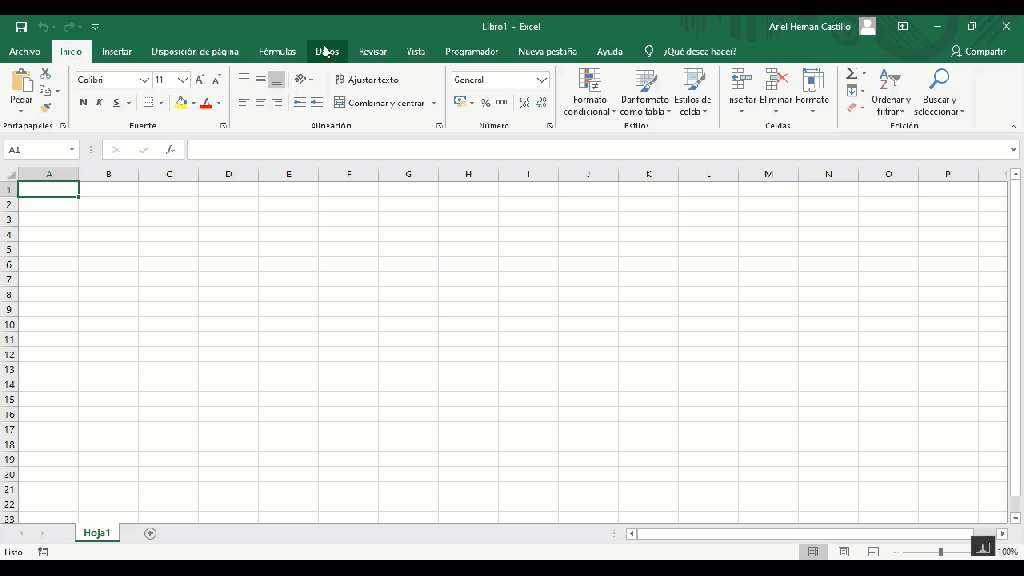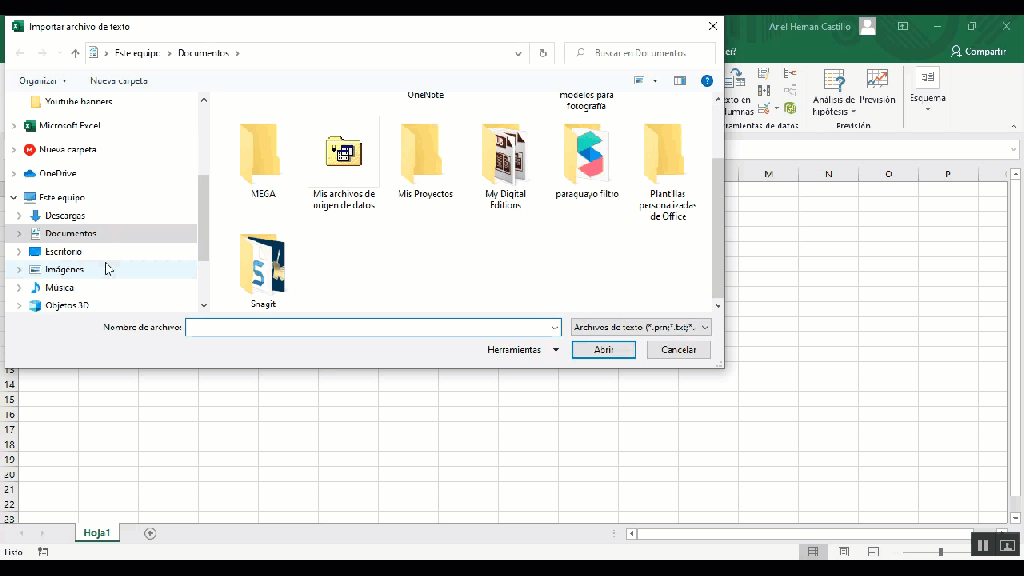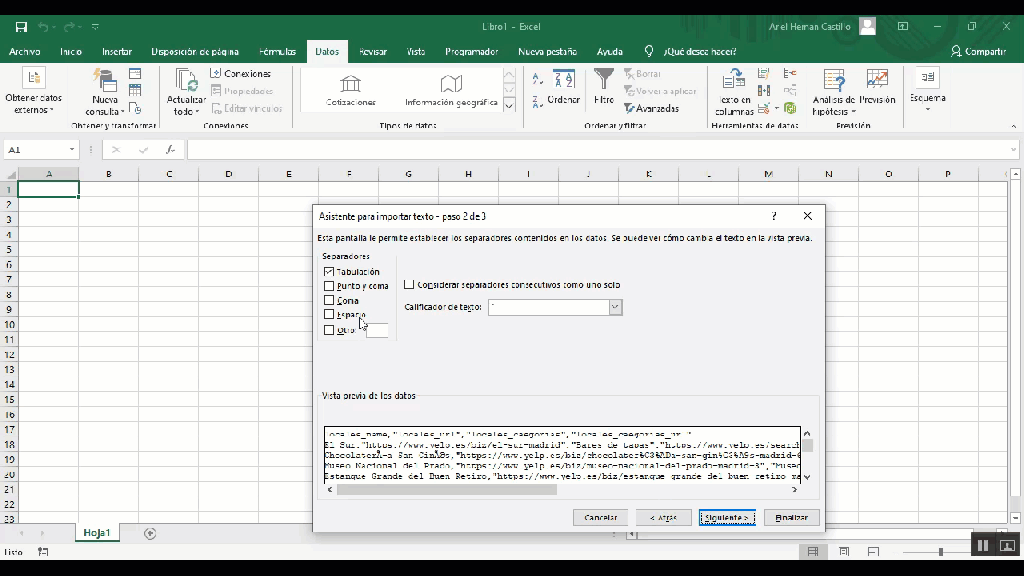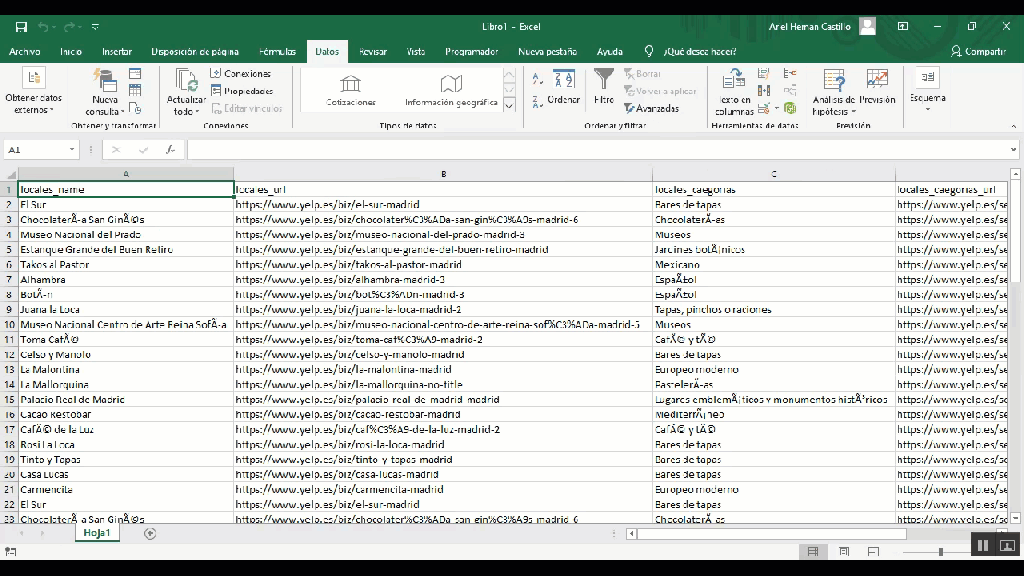
- Una vez que tus datos estén listos para descargar, haga clic en el botón CSV / Excel. Ahora puede guardar y cambiar el nombre de su archivo.
Dependiendo del sitio web desde el que esté extrayendo datos, es posible que su archivo CSV no se muestre correctamente en Excel.
Si se encuentra con estos problemas, puede resolverlos rápidamente utilizando la función obtener datos en Excel.
Y eso es todo lo que hay que hacer.
Ahora puede usar el poder del web scraping para recopilar información de cualquier sitio web, tal como lo hicimos en este ejemplo.
Web Scraping vs Web Crawling: ¿Cuál es la diferencia?
Si bien estos términos comparten muchas similitudes, existen diferencias clave que los distinguen.
Analicemos las definiciones de ambos términos y observemos las diferencias entre ellos.
Un aspecto clave de Web Scraping es que a menudo se realiza con un enfoque centrado. Esto significa que los proyectos de Web Scraping buscan extraer conjuntos de datos específicos de un sitio web para su posterior análisis.
Por ejemplo, una empresa puede extraer detalles de productos de computadoras portátiles que figuran en Amazon para descubrir cómo posicionar su nuevo producto en el mercado.
El Web Crawling se refiere al proceso de usar bots (o arañas) para leer y almacenar todo el contenido en un sitio web con fines de archivo o indexación.
Los motores de búsqueda (como Bing o Google) utilizan el web crawling para extraer toda la información de un sitio web e indexarla en sus motores de búsqueda. Así es como Google puede saber qué páginas tendrán la información que está buscando.
En este punto, es posible que ya pueda notar la diferencia entre Web Scraping y Web Crawling. Incluso si ambos términos se refieren a la extracción de datos de sitios web.
Un rastreador Web Crawling generalmente pasará por cada página de un sitio web. Por otro lado, Web Scraping se centra en un conjunto específico de datos en un sitio web.
En resumen, Web Scraping tiene un enfoque y un propósito mucho más centrado, mientras que Web Crawling escaneará y extraerá todos los datos en un sitio web.
Web Scraping vs Data Mining: ¿Cuál es la diferencia?
El Web Scraping se refiere al proceso de extraer datos de sitios web y estructurarlos en un formato más conveniente. No implica ningún procesamiento o análisis de datos.
La minería de datos o Data Mining se refiere al proceso de analizar grandes conjuntos de datos para descubrir tendencias y conseguir conocimientos valiosos. No implica ninguna recopilación o extracción de datos.
La minería de datos no implica la extracción de datos. De hecho, el web scraping podría usarse para crear los conjuntos de datos que se usarán en el Data Mining.
Web Scraping como Herramienta para tu estrategia de Marketing

Después de todo, el marketing solo se vuelve cada vez más basado en datos. Analicemos cómo los profesionales de marketing pueden aprovechar el web scraping.
Construir una lista de correo electrónico
El correo electrónico como canal de marketing ha mantenido su prevalencia durante casi décadas.
Una buena lista de correo electrónico que responda y convierta no tiene precio. Como resultado, la creación de listas de correo electrónico de alta calidad es una prioridad para los vendedores en todas partes.
El Web Scraping puede automatizar y acelerar sustancialmente el proceso de creación de una lista de correo electrónico.
Web scraping del contenido del blog
Contenido, otro pilar principal del marketing moderno. Pocas cosas pueden atraer tráfico constante a bajo costo a tu sitio web como un buen contenido.
Desde artículos instructivos hasta guías de ayuda, las publicaciones de blog pueden colocar a tu empresa en la primera página de Google y generar tráfico y conversiones constantes.
Como resultado, al planificar tu estrategia de contenido, es bueno saber qué han hecho tus competidores en el pasado.
Con un web scraper, puedes crear un proyecto simple para raspar todos los títulos de blog de su competencia , URLS, Meta Tags y más.
Esto le daría una valiosa base de datos de palabras clave y temas para trabajar de inmediato.
Web Scraping de datos de Twitter
La gente tuitea mucho .
A veces, tuitean demasiado. Sin embargo, el valor de los datos ocultos dentro de sus tweets no cambia.
Utilizar las redes sociales para el análisis de sentimientos o el análisis de mercado es una práctica tan antigua y valiosa como las redes sociales en sí.
¿De qué están tuiteando los influencers en tu industria?
¿Cuáles han sido los tweets más exitosos de tu competencia? ¿De qué trataban esos tweets?
Estas son todas las ideas valiosas que puedes obtener scrapeando Twitter.
Extraer los datos de Reddit
¿Qué sucede si deseas obtener información sobre comunidades enteras en lugar de individuos?
Afortunadamente, hay un subreddit para todo.
Con el web scraping, puedes descubrir rápidamente los temas que le interesan a su mercado objetivo.
Todo lo que tiene que hacer es encontrar el subreddit adecuado para la comunidad a la que se dirige.
- ¿Qué temas a menudo reciben una gran cantidad de votos a favor?
- ¿Qué temas no son tan populares o son rechazados con frecuencia?
- ¿Alguno de sus competidores publica activamente en estos subreddits?
Investigación de mercado / Análisis de la competencia
El Web scraping también se puede usar para extraer datos valiosos sobre su mercado o industria.
Por ejemplo, supongamos que tiene un negocio de comercio electrónico que vende camisetas de clubes o computadoras portátiles en línea.
Tener acceso a los datos de Amazon en su catálogo de computadoras portátiles, incluidos los detalles del producto, precios, puntajes de revisión, detalles de entrega y más, sería increíblemente valioso.
Puedes utilizar estos datos para generar información sobre cómo posicionar y publicitar tu producto de manera efectiva.
Generación de leads con web scraping: miles de leads de calidad en pocos minutos
Un lead es un usuario que ha entregado sus datos a una empresa y que, como consecuencia, pasa a ser un registro de su base de datos con el que la organización puede interactuar.
La generación de leads es una de las partes más importantes de cualquier proceso de ventas.
Pero crear listas con clientes potenciales de calidad a menudo no es fácil. De hecho, algunas compañías hacen todo su trabajo para generar clientes potenciales y vendérselos para obtener ganancias. Después de todo, ¿quién tiene tiempo para crear estas listas masivas mientras también realiza llamadas de ventas y hace un seguimiento con compradores potenciales?
Sin embargo, hay formas de optimizar el proceso y evitar al intermediario. La mejor opción es el web scraping.
Puede usar parsehub u otro para extraer datos clientes potenciales en línea de forma gratuita y sin tener que escribir ningún código. Esto puede darte acceso a toda la información de contacto en un sitio web en una práctica hoja de cálculo en tu computadora.
Generación de leads con web scraping
La información existe en todo el Internet, desde sitios de directorio hasta plataformas de redes sociales. Cuanto mejor recopile y utilice esta información, más exitosos serán tus esfuerzos de ventas.
Además, con el web scraping, puedes determinar de dónde provienen tus clientes potenciales . Esto tiene un impacto directo en la calidad del cliente potencial y, como saben, mejores clientes potenciales generan más ventas.
Por el contrario, es menos probable que conozca el origen de una lista de clientes potenciales comprados a otra persona.
Por dónde empezar: encontrar un sitio web objetivo
Por lo general, puede encontrar información sobre clientes potenciales en línea visitando sitios web específicos de la industria, plataformas de redes sociales o directorios de negocios.
Asegúrese de recopilar la biografía, la información de contacto y los enlaces de las redes sociales para cada cliente potencial de ventas y cualquier otra información que lo ayudará a conocer mejor a su cliente potencial.
Asegúrese de hacerse estas preguntas:
- ¿Hay algún patrón en el tipo de clientes que ya me están comprando? ¿De dónde están viniendo?
- ¿Dónde pasan el tiempo mis clientes potenciales ?
- ¿Hay algún cliente que esté haciendo lo que usted quiere que haga con su producto o servicio pero en otro lugar?
- ¿Hay directorios, plataformas de redes sociales o foros con mis clientes ideales?
Para poner en marcha el trabajo creativo, revisemos algunos lugares comunes para buscar leads de alta calidad.
Yellow Pages
yellow pages podría ser uno de los directorios de negocios más grandes en la web, especialmente en América del Norte. Si está buscando clientes potenciales en la industria de servicios, este es el mejor lugar para comenzar a recopilar nombres, direcciones, números de teléfono y correos electrónicos.
Yelp
Yelp es otro de los favoritos del mundo de los directorios de negocios, con más de 90 millones de visitantes mensuales a través de su aplicación y sitio móvil.
Aunque la mayoría de las personas asociaron directamente Yelp con restaurantes y bares solamente, el sitio en realidad tiene listados para todo tipo de negocios, incluidos médicos, dentistas, reparaciones, electricistas, mudanzas y más.
Lo mejor de Yelp es su comunidad de moderadores y puntuadores cómo puedse usar sus comentarios a su favor. Junto con la información de contacto de la empresa, también puedes extraer sus puntajes de revisión para priorizar las empresas que son valoradas por sus clientes y, por lo tanto, es más probable que permanezcan en el negocio durante mucho tiempo.
Después de todo, lo único mejor que una venta es una venta repetida.
Influenciadores
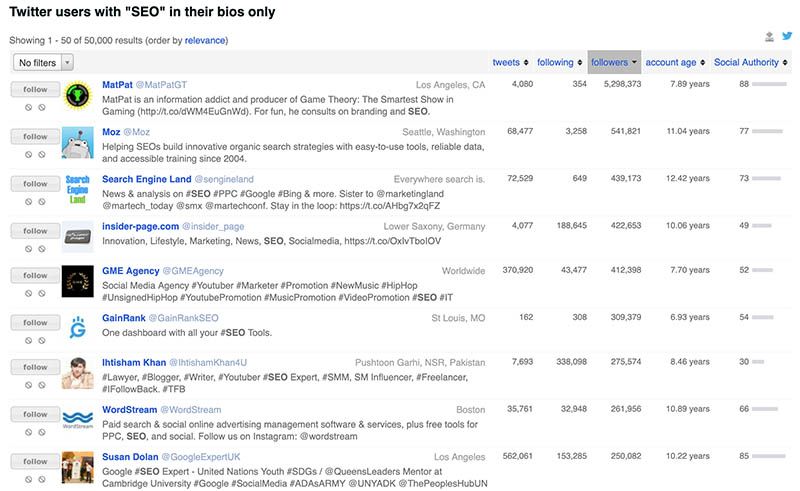
Vayamos con un ejemplo diferente. Tal vez desee apuntar a grandes influenciadores en una industria específica y presentarles su producto.
Puede usar una herramienta como FollowerWonk para obtener una lista de todos los influencers de Twitter para un tema específico. Por ejemplo, a continuación hemos elaborado una lista para el principal influyente de SEO en Twitter. Esto podría ser increíblemente valioso si está vendiendo una herramienta o servicio en la industria de SEO.
¿Es legal el web scraping?
La verdad es que la legalidad del web scraping todavía está relativamente en el aire.
Lo que significa que actualmente no existen leyes específicas que se refieran a la legalidad de esta práctica. Por lo tanto, no es legal ni ilegal.
Sin embargo, hay algunos casos legales notorios relacionados con la extracción de datos de la web. Muchos expertos legales también están presionando para que la Corte Suprema de los EE. UU. Tome una posición oficial sobre este tema.
Extraer información disponible públicamente
Otro factor a tener en cuenta es el tipo de datos que estarías extrayendo En este caso, siempre nos referimos a datos disponibles públicamente.
Estos son datos que el propietario de dichos datos ha hecho públicos. La información privada y filtrada no se considera información disponible públicamente.
Después de todo, consideramos que la información privada es confidencial y extraer datos privados puede ocasionarte muchos problemas. Solo recuerde el escándalo de Cambridge Analytica donde recolectaron datos privados de los usuarios de Facebook.
¿Es ético el web scraping?
Consideramos que la extracción de datos disponibles públicamente es ético.
Después de todo, estos datos ya están disponibles de forma gratuita. No hay nada que le impida anotar manualmente los precios de los productos de Amazon en una hoja de cálculo. El web scraping simplemente automatiza este proceso.
Al mismo tiempo, hay que oponerse al abuso de las herramientas de extracción de datos web. Por ejemplo, no usar estas herramientas para obtener correos electrónicos con fines de spam masivo. De hecho, hay formas más éticas de utilizarlo para el marketing por correo electrónico.
Al final del día, si los datos que estás extrayendo están disponibles públicamente y no estás buscando abusar de las herramientas de web scraping, podemos considerarlo ético.